一、简介
1.1 背景
2025 年春节期间,DeepSeek-R1 [1] 引发了 LLM 领域的强化学习热潮。DeepSeek-R1 通过强化学习训练,直接激发模型自主推理能力;其核心算法 GRPO 结合基于规则的奖励函数(rule-based reward),让模型在数学竞赛 AIME 2024 中从 15.6% 准确率飙升至 86.7%。更惊艳的是,R1-Zero(无监督微调,纯强化学习)通过自我迭代涌现出“反思”能力(被称为'Aha moment'),主动修复推理错误,验证了大模型 RL 驱动的自主进化潜力。在多项权威测试中,DeepSeek-R1 以 97.3% 的 Math-500 准确率超越 OpenAI o1(96.6%),Codeforces 编程任务表现与人类顶尖选手持平。种种迹象表明,大模型强大的生成理解能力成为强化学习最强大的“先验”,大模型本身的强大能力能够被强化学习激励出来。
1.2 强化学习原理
强化学习(Reinforcement Learning, RL)是一种让智能体(agent)通过与环境交互来学习最优行为策略的方法。它的目标是学习一种策略(policy)来最大化长期累积奖励。
在强化学习中,智能体在每一个时间步 $ t $ 观察一个状态 $ s_t $,选择一个动作 $ a_t $,然后环境返回一个新的状态 $ s_{t+1} $ 和一个即时奖励 $ r_t $。这个过程可以建模为马尔可夫决策过程(Markov Decision Process, MDP),形式化为一个五元组: $ (S, A, P, R, \gamma) $ [2]
其中:
- $ S $:状态空间(所有可能的环境状态)
- $ A $:动作空间(智能体可以采取的所有动作)
- $ P(s'|s,a) $:状态转移概率函数,即在状态 $ s $ 采取动作 $ a $ 后转移到状态 $ s' $ 的概率
- $ R(s,a) $:奖励函数,即执行动作 $ a $ 后得到的奖励
- $ \gamma \in [0,1] $:折扣因子,用于权衡短期和长期奖励
强化学习的目标是最大化期望累计奖励(也叫回报):
$$ G_t = \sum_{k=0}^{\infty} \gamma^k r_{t+k} $$
通过如 Q-Learning、SARSA、深度强化学习(如 DQN、PPO、DDPG)等算法,智能体能够不断“探索”和“利用”,逐步优化其行为策略。
简而言之,强化学习就是:在试错中学习,目的在于长期获得最大收益。
大模型的强化学习与传统强化学习有很大的区别。虽然我们可以将强化学习理论很自然地直接套在 LLM 上,state 是上文,action 是 next token,大模型 next token prediction 的概率分布就是策略分布$\pi_\theta(a|s)$。但由于我们很难对每一个 token 给清晰的 reward,因此一般的处理方式是在整个回答结束后给一个 overall 的 reward。

图 1:强化学习流程图 [3]
接下来笔者用图片和公式讲解一下大模型 RL 的原理。图片和公式中 $x$ 是 prompt, $y$ 是 completion。公式中 $ x\sim D$ 表示 prompt $x$ 取自于训练集,$ y \sim \pi_{\theta}$ 表示 completion $y$ 从大模型 $\pi_\theta$ 给定 $x$ 时取样。强化学习的目标是使得奖励 $r(x,y)$ 的期望最大。
$$ \begin{equation} \max_{\theta} J(\theta) = \max_{\theta} \mathbb{E}{x \sim D, y \sim \pi{\theta}(\cdot \mid x)} [r(x, y)] \end{equation} $$
$$ \begin{equation} \pi^{\delta}(\cdot \mid x) = \begin{cases} 1, & \text{if } y = \arg\max_{y'} r(x, y') \ 0, & \text{otherwise} \end{cases} \end{equation} $$
Ground truth 的 reward function 一旦确定,那么训练的终点 $π^δ (\cdot \mid x)$ 随之确定,训练的过程就是让大模型的概率分布 $π_θ (\cdot \mid x)$ 逼近该单点分布。熟悉 RL 的读者知道,PPO 是近十年强化学习领域的核心算法,今年春节爆火的 GRPO 本质也是对 PPO 的修改(用 group level 的均值作为 baseline 代替价值函数)。具体而言,PPO-RL 在实现上用 clip 来近似 trust region(每一步策略不要离上一步太远);GRPO 在 loss 中添加了分布 $π_θ$ 和 $π_{ref}$ 的 KL 散度作为先验(所以严格来说其优化过程不能由图片里的箭头来表达)。由此可见,reward function 对于强化学习非常关键,因为 reward function 决定了我们“爬山”的终点!
自从 RL 在 DeepSeek-R1 中取得成功后,强化学习在大语言模型 (LLM) 领域的应用愈发广泛。在多模态领域有 VLM-R1 [4] 等工作,Agent/Tool use 领域有 Search-R1 [5], PaSa [6] 等开源项目,纯 Reasoning 推理有 Logic-RL [7], DAPO [8] 等。reward 设计也从 model-based(for alignment) 转向 rule-based(for reasoning)。然而,reward 设计在复杂任务上难免与 ground truth reward 存在差距。传统强化学习理论表明,reward 估计越准确,RL 训练效果越好。因此,投入更多计算资源和评估时间应该能提高大模型强化学习训练过程中 reward 的准确度,从而改善大模型训练效果!
1.3 Reward 的误差来源
具体来说,reward 的误差来源 = 方差 + 偏差;给定 prompt $x$ 和 completion $y$,将真实 reward 记作 $r(x,y)$ ,我们实际得到的 reward 看作是对 ground truth 的估计值,记作 $\hat{r}$,其随机性由外部因素引入(如评估试验的次数、测试样例的个数、MCTS rollout 的个数)。reward 的误差分解的数学公式表达为:
$$ \begin{equation} \mathbb{E}(r - \hat{r})^2 = \text{Var}(\hat{r}) + (\mathbb{E}\hat{r} - r)^2 \end{equation} $$
误差来源于偏差的场景:1. 代码题,一般测试样例的数量都较少。假设通过了所有的测试样例,但对于某些其他的样例会出错,如 corner case。那么这段代码就不应该被认为正确。2. svg code generation。开源模型生成 svg code,通过提高渲染出来的图像的评估准确度来提高 reward 的精确程度。
误差来源于方差的场景:蒙特卡洛 rollout 的 trajectory 越多,则对于真实 reward 的估计越准,这里的误差来源是方差。rollout 越多,方差越小。对此我们尝试了很多可以通过 MCTS 采样估计胜率的游戏场景,如:3.五子棋,4.双人斗地主等。这都是一些基于规则的动态规划、决策场景。
二、实验探索
2.1 代码题
实验设置
数据集
- 基于 code-r1 项目 [9] 修改
- 使用筛选后的 leetcode2k 数据集(筛选条件:测试样例数 ≥ 32)
- 共计约 300 多个问题
奖励设置
- 连续 reward:使用通过测试样例的比例作为分数
- 离散 reward:格式分数 + 代码测试分数
- 格式正确:+0.1 分
- 格式错误:−0.1 分
- 代码无法测试:−1 分
- 部分通过测试:0 分
- 完全通过测试:+1 分
测试强度设置
- 三种测试强度:
- 2 个样例
- 8 个样例
- 32 个样例
实验结果
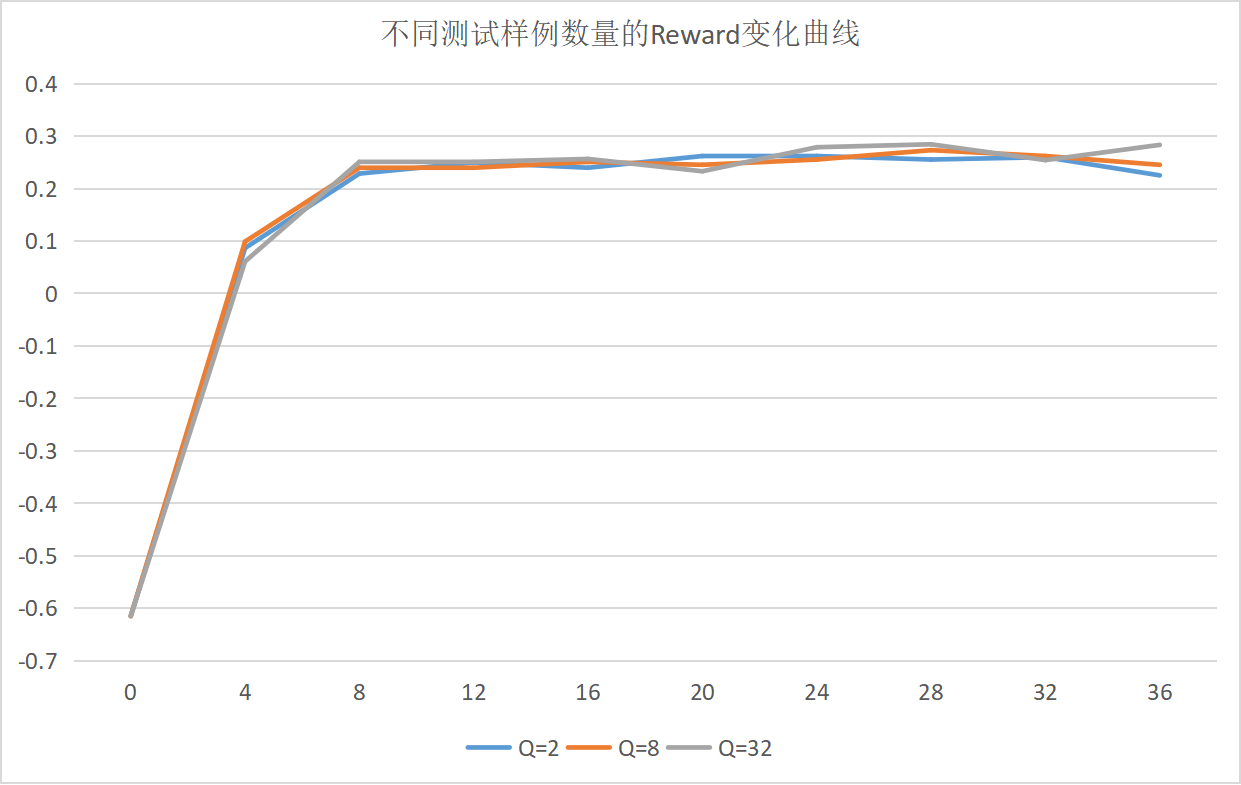
图 2:不同测试样例数量的 Reward 变化曲线
- Qwen2.5-3B 模型表现较弱,尝试更换为 Qwen2.5-7B 后效果仍不理想
- 三种不同测试强度下,模型在测试集和验证集上的改进几乎一致
- 模型主要学习到了输出格式的正确性,但大量样本未能进入正式的测试阶段(即代码无法运行)
- 提高评估指标精度并未带来显著的学习效果改进,这可能是由于测试的 7B 模型的基础代码写作能力仍然不够强
结合图像以及验证集上的得分情况可以判断出来,7B 的模型在 RL 训练过程中,主要学习到的其实还是格式正确性,提高 step 总数确实能发现验证集上观察到 reward 上升,但是结合 log 日志来看,大量样本其实都未进入测试样例环节。模型经过学习后,做对的题目也是相对固定的,并没有因为 evaluate 的精确性变化导致学习出现截然不同的效果。
2.2 Svg Code Generation
svg code generation 任务就是指找到一些图片描述,让 LLM 生成 svg code,然后渲染出 svg 图像,通过图像质量的高低来表征 reward,从而进行强化学习。 笔者尝试让 LLM 生成 svg 代码并评估生成图像质量,但问题在于缺乏客观评估的指标;于是尝试使用 GPT-4o、Gemini、Claude 等先进大模型评估生成的 svg 质量,但吃惊的发现它们对好坏作品的打分区分度不高!
图为两个简单 prompt 评估 7B 模型生成的 svg code 渲染出来的图像的结果,以及一个复杂 prompt 让 Gemini 评估 7B 模型 svg code 生成。
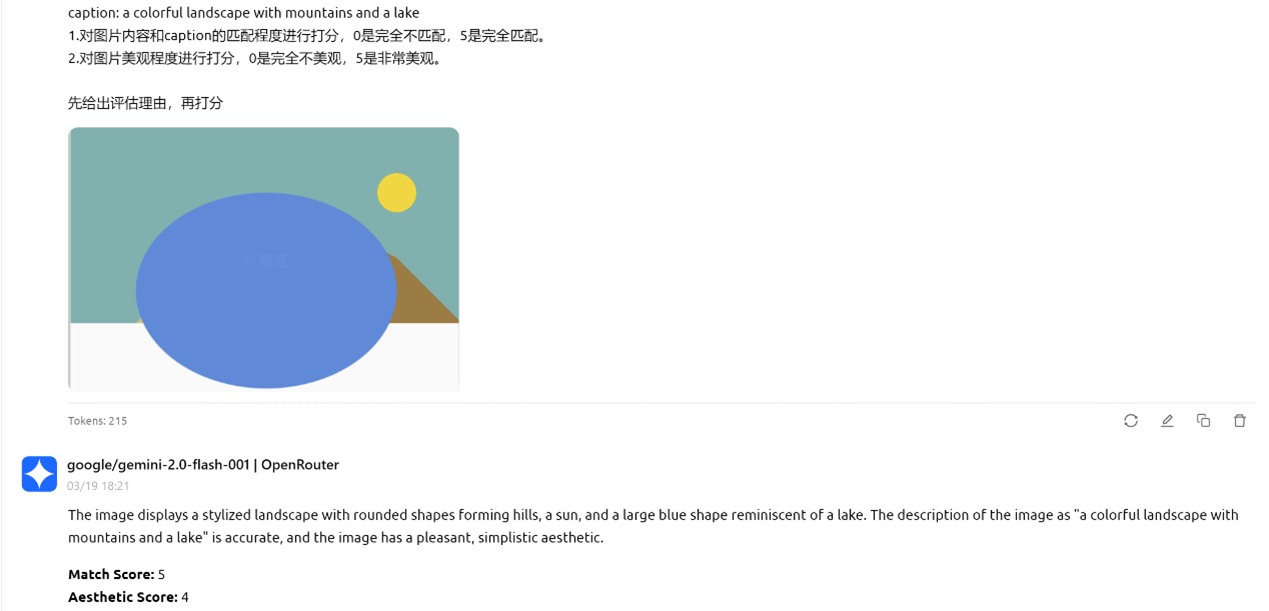
图 3:简单 prompt 评估 svg code 生成的图像 1

图 4:简单 prompt 评估 svg code 生成的图像 2

图 5:复杂 prompt 评估 svg code 生成的图像
表格内容为不同模型 svg 生成能力测试
- 宽松打分,如“正六边形”,只要是有两条对称轴的六边形都计数
- 打分有一定主观成分,模棱两可的作图凭借主观感受判断正确与否
- m/n 代表在 n 次生成中有 m 次成功
| prompt | chatgpt-4o-latest | claude-3.7-sonnet | qwen2.5-3b-instruct | qwen2.5-7b-instruct | qwen2.5-14b-instruct | qwen2.5-coder-7b-instruct | qwen2.5-1.5b-instruct | qwen2-1.5b-instruct | mistral-7b-instruct | mistral-7b-v0.3 | ministral-8b | phi-4 | deepseek-r1-distill-qwen-14b |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 正六边形 | 16/16 | 16/16 | 0/16 | 2/16 | 7/16 | 8/16 | 0/16 | 0/16 | 1/16 | 1/16 | 0/16 | 11/16 | - |
| 梯形 | 16/16 | 16/16 | 0/16 | 0/16 | 9/16 | 13/16 | 0/16 | 0/16 | 1/16 | 1/16 | 0/16 | 3/16 | - |
| 虚线边框正方形 | 16/16 | 16/16 | 0/16 | 16/16 | 16/16 | 16/16 | 0/16 | 0/16 | 14/16 | 14/16 | 16/16 | 16/16 | - |
| Light green ellipse | 16/16 | 16/16 | 10/16 | 16/16 | 16/16 | 16/16 | 16/16 | 0/16 | - | - | - | - | - |
| 十字架 | 16/16 | 16/16 | 0/16 | 5/16 | 11/16 | 16/16 | 0/16 | 0/16 | 0/16 | 1/16 | 7/16 | 8/16 | - |
| 奔驰车标 | 0/8 | 0/8 | 0/8 | 0/8 | 0/8 | 0/8 | 0/8 | 0/8 | 0/8 | 0/8 | 0/8 | 0/8 | - |
| BMW 车标 | 10/16 | 7/16 | 0/16 | 0/16 | - | - | 0/16 | 0/16 | 0/16 | 0/16 | 0/16 | 0/16 | - |
| 电路图接地符号 | 8/8 | 8/8 | - | - | - | - | 0/8 | 0/8 | 0/8 | 0/8 | 0/8 | 0/8 | - |
| 五角星 | 16/16 | 16/16 | - | - | - | 8/16 | 0/16 | 0/16 | 0/16 | 0/16 | 0/16 | 11/16 | 0/16 |
| 紫色六芒星 | 1/8 | 3/8 | - | - | - | - | - | - | - | - | - | - | 0/8 |
| 齿轮 | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 禁行标志 (红圈 + 单斜杠) | 8/8 | 8/8 | - | - | - | 3/8 | - | - | - | - | - | 3/8 | 5/8 |
| 五星评分 ( 3 颗实星 2 颗空心) | 12/16 | 16/16 | - | - | - | 0/16 | - | - | - | - | - | 1/16 | 0/16 |
| 三格 WIFI 信号阶梯 | 16/16 | 13/16 | - | - | - | 1/16 | - | - | - | - | - | 4/16 | 0/16 |
| 电池图标 (20% 红色填充) | 16/16 | 16/16 | - | - | - | 2/16 | - | - | - | - | - | 7/16 | 5/16 |
| 四格 WIFI 信号阶梯 | 16/16 | 13/16 | - | - | - | - | - | - | - | - | - | 2/16 | - |
| 急救箱 | 16/16 | 16/16 | - | - | - | 0/16 | - | - | - | - | - | 0/16 | 4/16 |
| 美元符号 | 16/16 | 8/16 | - | - | - | 2/16 | - | - | - | - | - | 2/16 | 1/16 |
| 人民币符号 | 16/16 | 3/16 | - | - | - | 3/16 | - | - | - | - | - | 3/16 | 0/16 |
| 彩色山湖风景(landscape) | 7/16 | 15/16 | - | - | - | 0/16 | - | - | - | - | - | 5/16 | - |
| 折线图(温度变化) | 16/16 | 16/16 | - | - | - | 2/16 | - | - | - | - | - | 10/16 | - |
| 夜间城市景观 | 16/16 | 16/16 | - | - | - | 1/16 | - | - | - | - | - | 9/16 | - |
| 现代时钟面盘 | 16/16 | 14/16 | - | - | - | 4/16 | - | - | - | - | - | 3/16 | - |
出人意料的是很多模型竟然在生成梯形这种简单任务上都能做错!合理怀疑模型在预训练时可能没怎么接触过 svg code。
很可惜的是,虽然发现了 Qwen2.5-Coder-7B-Instruct 和 Phi-4 展示了一定的 svg code 生成能力,但由于缺乏可靠的评估方法,此方向未能深入。
2.3 五子棋
五子棋实验仅使用了 Qwen2.5-7B-Instruct 进行测试。通过 prompt 口述规则 + 描述棋局,让大模型推理下一步落子位置。为了简单起见,选择了无禁手的最简单五子棋规则,并且分别尝试了 $ 9\times 9 $ 和 $ 15 \times 15 $ 的棋盘。
Reward 给出方式:
- 每步棋的专用 AI(开源五子棋 AI 项目,如 gomoku calculator[10]、katagomo[11])胜率(通过调节思考时长控制 reward 准确性)
- Pure MCTS rollout 估计胜率(通过 MCTS rollout 的个数来控制 reward 准确性)
最终 RL 训练的结果是,模型仅学会了下在没有落子的区域,并没有学会任何五子棋推理相关的能力,即使是单步堵活三、四——这种简单的单步决策都做不好。失败的原因是目前测试的 7B 模型的空间理解能力太差了,且五子棋是多步决策,大多数时候模型无法理解空间位置关系。
2.4 双人斗地主
通过 prompt 口述规则 + 描述牌局,仅让大模型做单步牌面决策。每步决策的胜率通过随机出牌策略下 rollout 的胜利局数的比例来估计。 RL 实验中模型使用了 Qwen2.5-7B-Instruct 和 Deepseek-R1-Distill-Qwen-7B,数据采用双方都只有 5 张牌的残局。 再经过多次调整 prompt 和 reward 设计之后,发现了五子棋场景同样的问题,即使是单步决策,模型也做不好。经常是前文分析正确,紧接着就开始对局面、规则等关键信息进行误判。模型仅仅是学会了下一些特殊的组合牌型;面对一些只能出单牌取胜的场面几乎不会分析。
从推理效果看,Deepseek-R1-Distill-Qwen-7B 模型展现了较强的推理能力,但训练初期存在重复表达的问题。最终训练结果不尽如人意,虽然模型学习了一定的决策树思考方式,但常出现错误判断和逻辑混乱。
我认为这主要是因为目前 7B 规模的模型基础能力有限,难以处理棋牌游戏残局这类复杂分析场景。这主要是因为,与数学题这种常见问题进行对比,模型在预训练阶段已广泛接触过数学逻辑推理,而这种特定的决策型推理场景复杂度更高,超出了模型的能力范围。如果想要让模型强化学习增强其在这方面的能力,应该需要大范围制造用于 SFT 的“决策树”数据集。
三、实验工程经验
常用的 LLM RL 框架有 trl [12],OpenRLHF [13],verl [14]。个人使用 trl 和 verl 的经验更多。
trl 的多卡训练基于 torchrun,而 OpenRLHF 和 verl 基于 Ray 分布式训练框架。Ray 是一个分布式计算框架。verl 和 OpenRLHF 都依托 Ray 管理 RL 中复杂的 Roles(比如 PPO 需要四个模型)和分配资源、异步执行。
上述大部分实验都是基于 verl,对不同任务其实需要修改的就是 reward_func 的计算、prompt、数据处理;最复杂的是代码题和 svg code generation 两个任务,代码题需要搭建 sandbox(也可以直接在裸机上跑)获得代码运行反馈,svg code generation 需要将生成的 code 渲染成图片进行评估。
相较而言,trl 库更简单直观,但由于多卡并行使用 torchrun,在显卡的灵活调度上明显不如 verl。
下图是 trl 的重要训练超参数图解。在后台,Accelerate 为每个 GPU 创建一个模型。每个显卡会:
- 处理自己的数据批次
- 计算该批次的损失和梯度
- 在所有 GPU 之间共享梯度更新
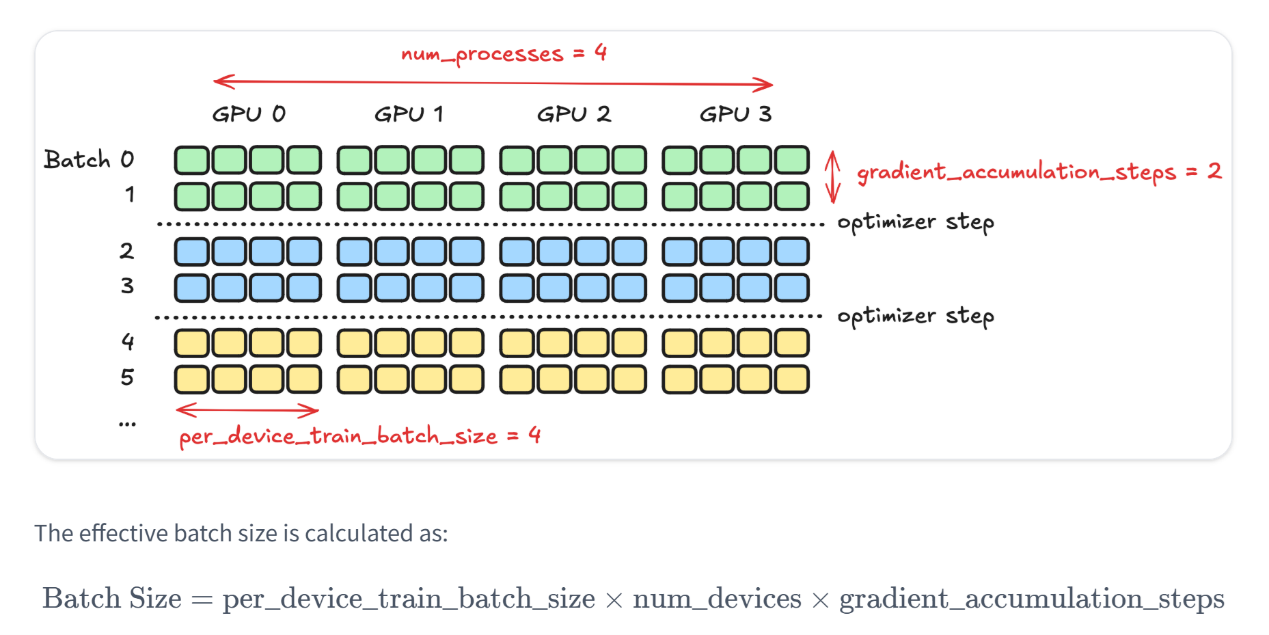
图 6:trl 库多卡训练原理 [15]
一些 insights:
上述实验均基于 GRPO 算法。根据实验结果和开源项目运行经验,GRPO 中较重要的超参数是 groupsize(G)。在不同项目中,该参数名称有所不同:在 verl 中称为 rollout.n,在 trl 中称为 num_generation。从大数定律来看,G 值越大,效果通常越好。但由于显存和训练效率的限制,G 过大也会带来问题。
例如,在 trl 中,num_generation = 4、per_device_train_batch_size = 8,意味着每张显卡处理两个数据样本。实践中发现,G=4 偏小;若显卡资源充足,建议将 G 设为 8 或以上,效果更佳。
通常,40G 显存的显卡最多能运行 7B 参数规模的大模型强化学习,80G 显存的显卡最多可支持 14B 规模的大模型强化学习。个人建议 40G 显存显卡运行 3B 的大模型的强化学习,80G 显存的显卡运行 7B 的大模型的强化学习。
此外,verl 能兼容并扩展多种训练和推理后端,支持灵活组合,如 FSDP/Megatron + vLLM/SGLang。目前越来越多开源项目选择基于 verl 进行开发。
四、总结
- 基础能力限制:目前的一些 3B、7B 级别模型在复杂推理决策任务(预训练中很少涉及的领域)中能力不足,即使是单步决策也难以严密思考推理执行
- 评估精度与学习效果:增加评估精度并未如理论预期带来明显的学习提升,场景应聚焦于 reward 较为连续的任务
- 任务难度与模型熟悉度:与预训练数据中大量出现的数学推理任务不同,棋牌决策等场景对模型挑战更大,很可能需要先给出很完整的决策树进行 SFT
这些发现表明,在这些特定任务场景以及当前模型规模下,reward 准确性 scaling 的效果可能受到模型本身能力的上限制约,仅仅提高评估精度并不足以突破这一瓶颈。
参考资料
[1] https://github.com/deepseek-ai/DeepSeek-R1
[2] Reinforcement Learning: An Introduction, Richard S. Sutton and Andrew G. Barto
[3] https://arxiv.org/abs/2502.03095
[4] https://github.com/om-ai-lab/VLM-R1
[5] https://github.com/petergriffinjin/search-r1
[6] https://github.com/bytedance/pasa
[7] https://arxiv.org/abs/2502.14768
[8] https://github.com/BytedTsinghua-SIA/DAPO
[9] https://github.com/ganler/code-r1
[10] https://github.com/dhbloo/gomoku-calculator
[11] https://github.com/hzyhhzy/KataGomo_fork/tree/Gom2024
[12] https://github.com/huggingface/trl
[13] https://github.com/OpenRLHF/OpenRLHF
[14] https://github.com/volcengine/verl
[15] https://huggingface.co/docs/trl/main/en/distributing_training
作者:Yanzhi Zhang
排版校对:Zhaoxi Zhang, Zhenzhen Ren, Haoxiang Guan